
Pod Configuration
| CPU | Memory |
|---|---|
| 0.5 | 512M |
Testing Tool
Alibaba Cloud PTS
| Concurrency | Duration | Source | Test Endpoint |
|---|---|---|---|
| 100 | 2 min | Public | /api/welcome |
Note: 100 concurrency was determined after initial testing as the maximum load the pod could handle without errors (200 concurrency caused significant RT increases).
Service Startup
RoadRunner architecture:
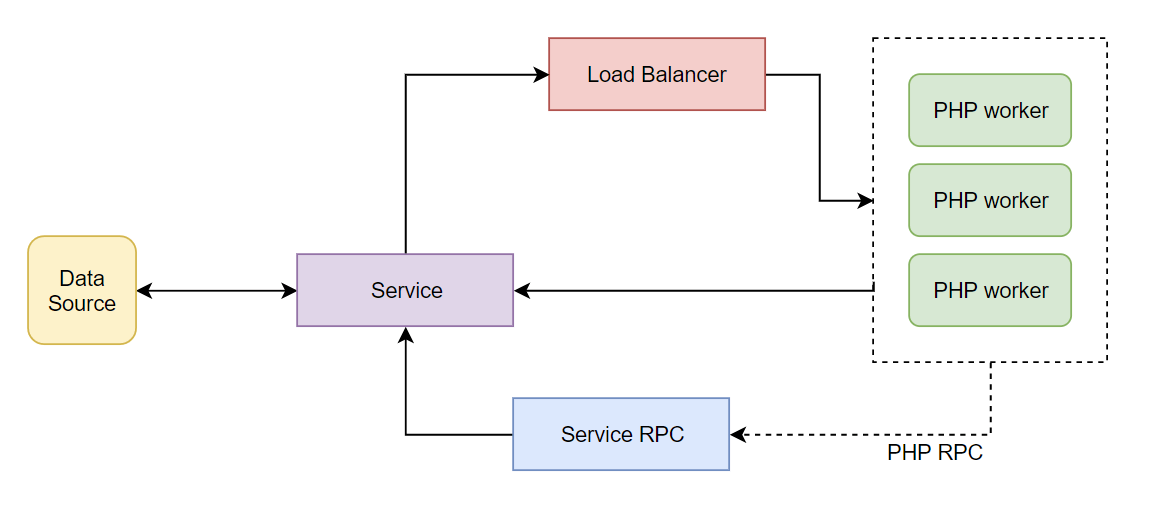
Laravel Octane natively supports RoadRunner. Start the HTTP service with:
php artisan octane:start --server=roadrunner --host=0.0.0.0 --port=8080 --rpc-port=6001 --workers=1 --log-level=warn
--max-requests=50000 --rr-config=/var/www/.rr.yaml
Key Concepts
QPS(TPS) = Total Requests / Time (seconds)
Concurrency (client-side) and QPS (server-side throughput) are not directly correlated.
Test Results
Official recommendations: workers = CPU cores, enable keep-alive for 40% performance gain, set max-requests to 0 or a large value (we used 50000).
| Workers | Max Requests | Success Rate | Avg RT(ms) | Total Requests | TPS (Avg/Peak) | Preview |
|---|---|---|---|---|---|---|
| 1 | 50000 | 100% | 1378 | 8665 | 72/118 | 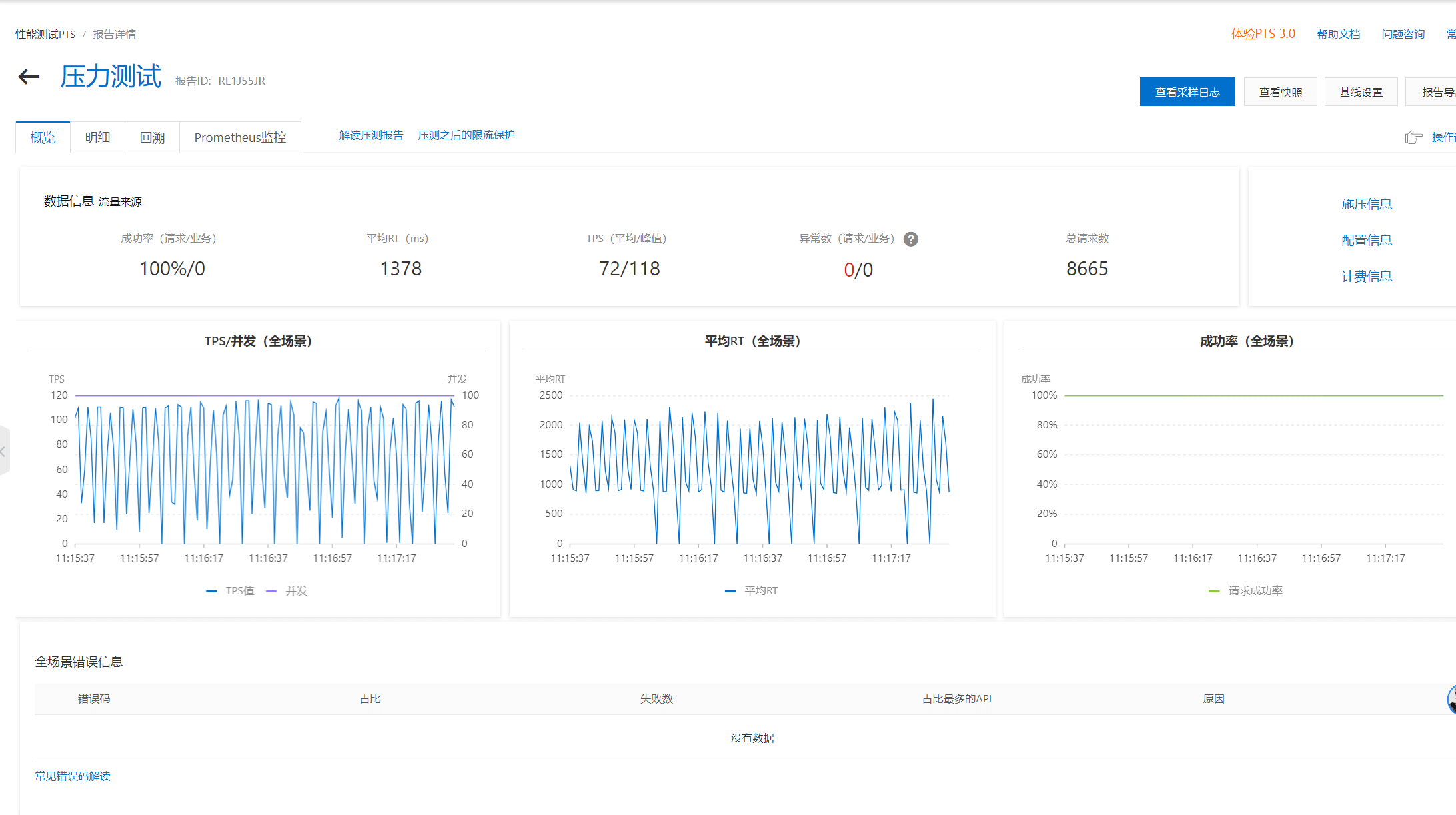
|
| 2 | 50000 | 100% | 1090 | 10000 | 91/170 | 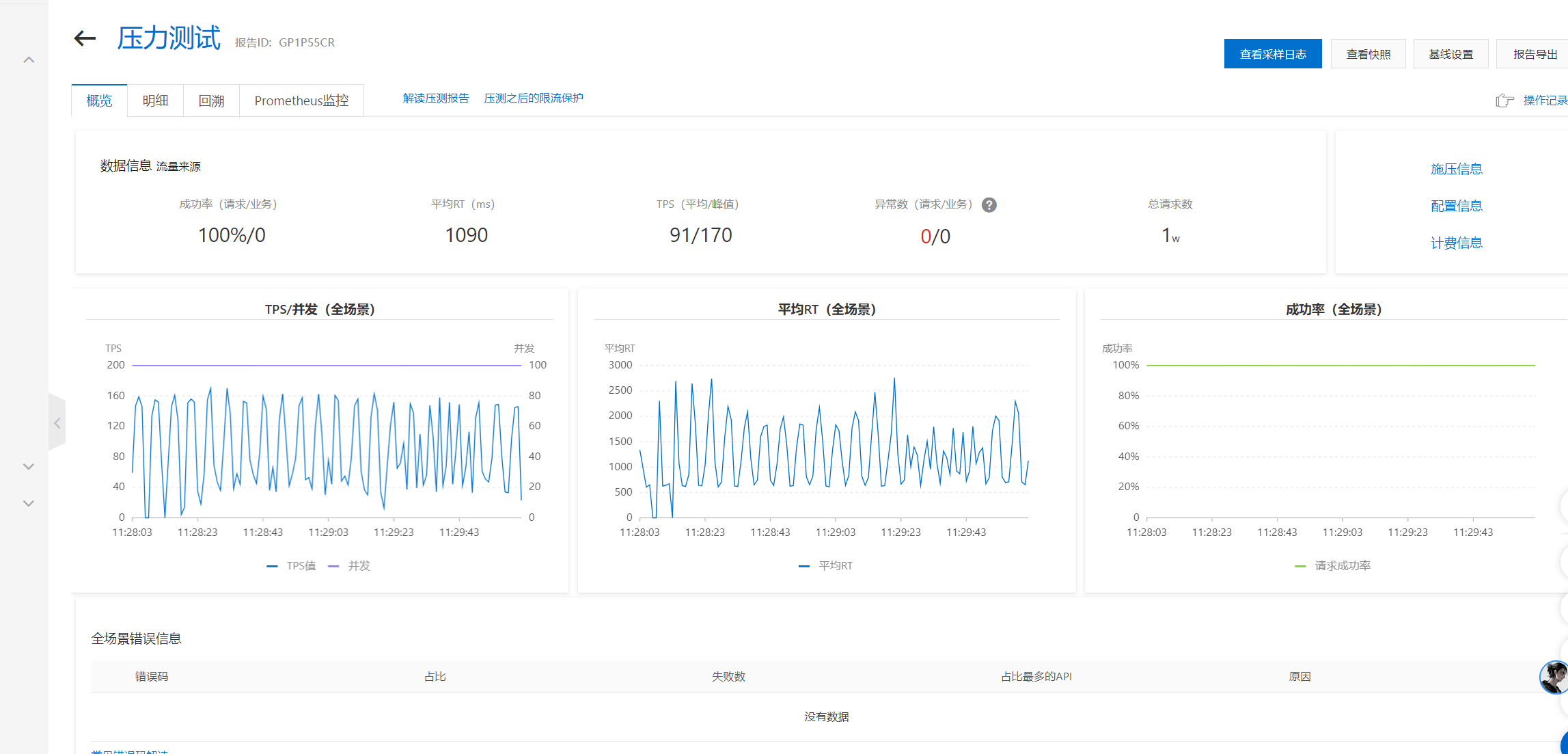
|
| 4 | 50000 | 100% | 1307 | 9042 | 76/133 | 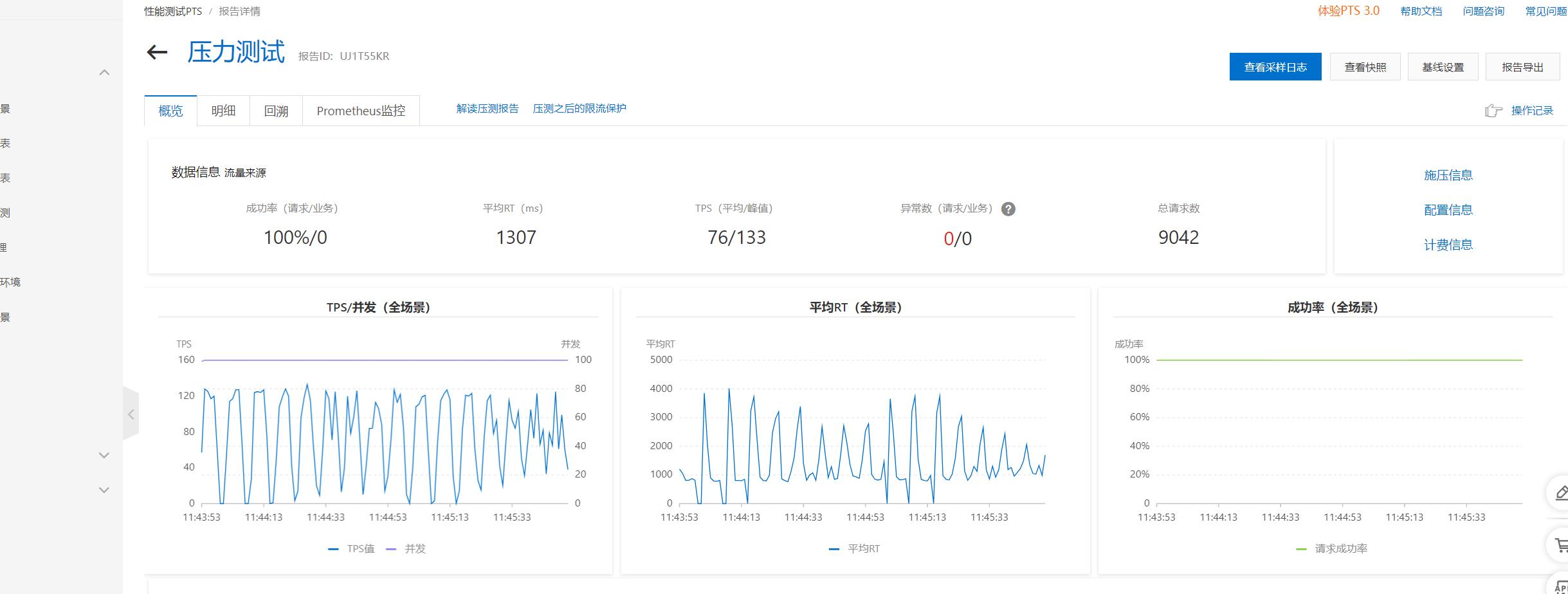
|
| 8 | 50000 | 99.16% (OOM & timeouts) | 2161 | 5501 | 46/78 | 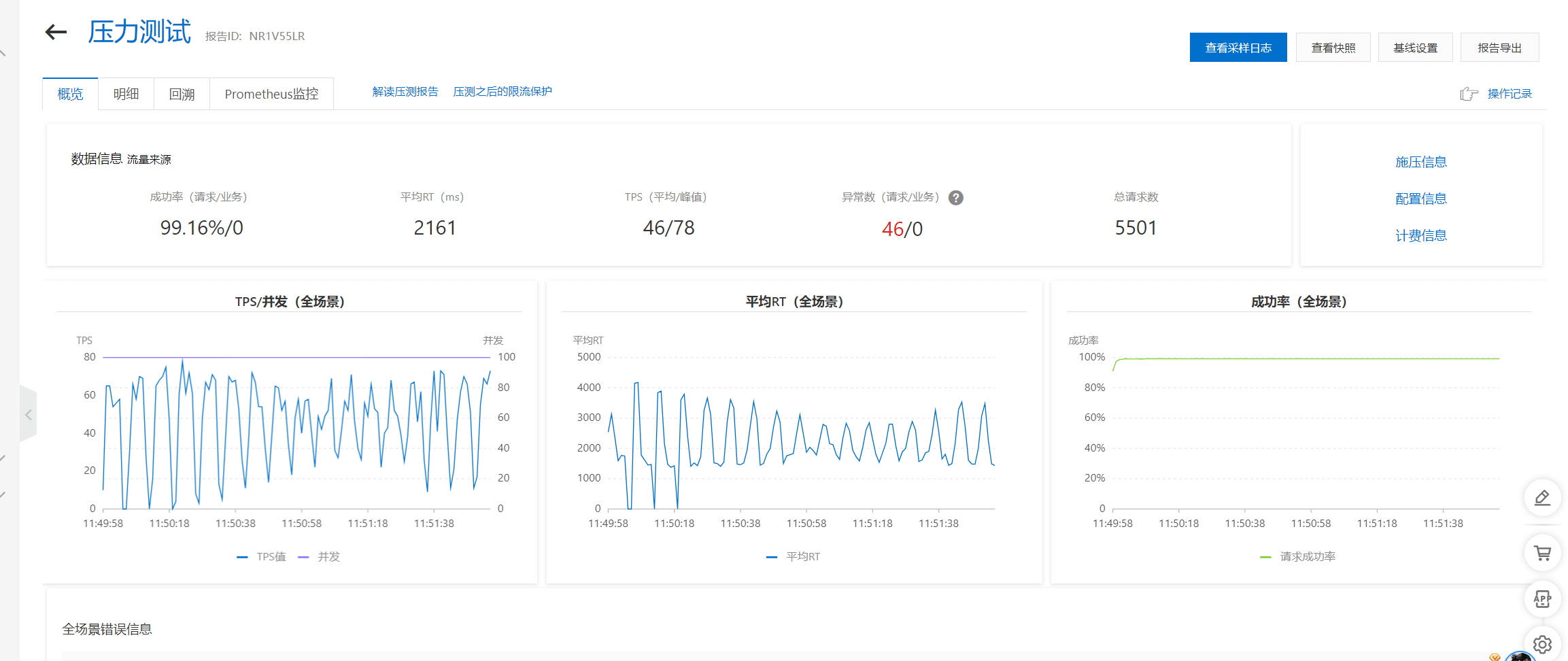
|
| 2 | 500 | 93.68% (worker recycling) | 1567 | 7508 | 65/174 | 
|
| 2 (no opcache) | 50000 | 100% | 1118 | 10000 | 89/190 | 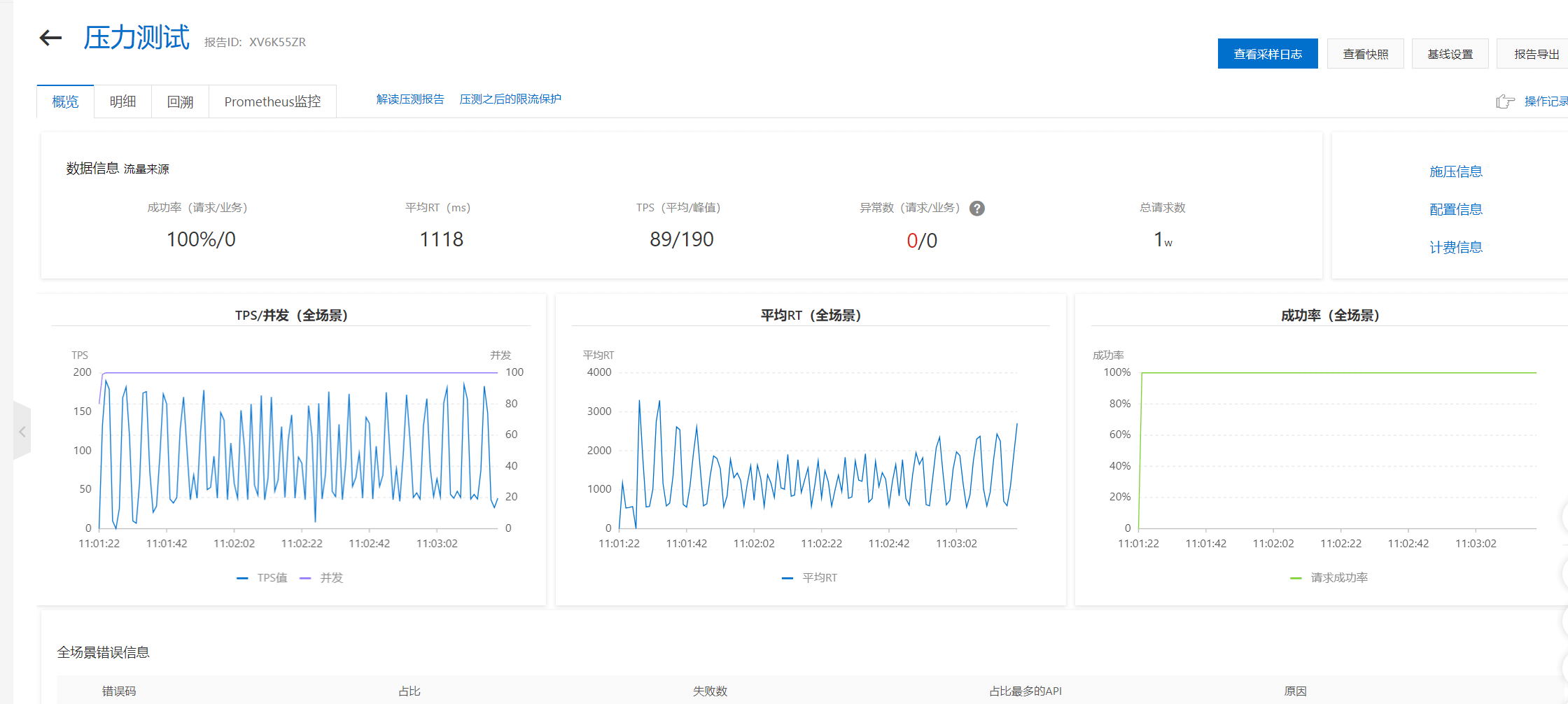
|
Resource Utilization
- CPU utilization remained stable. Memory increased with more workers.
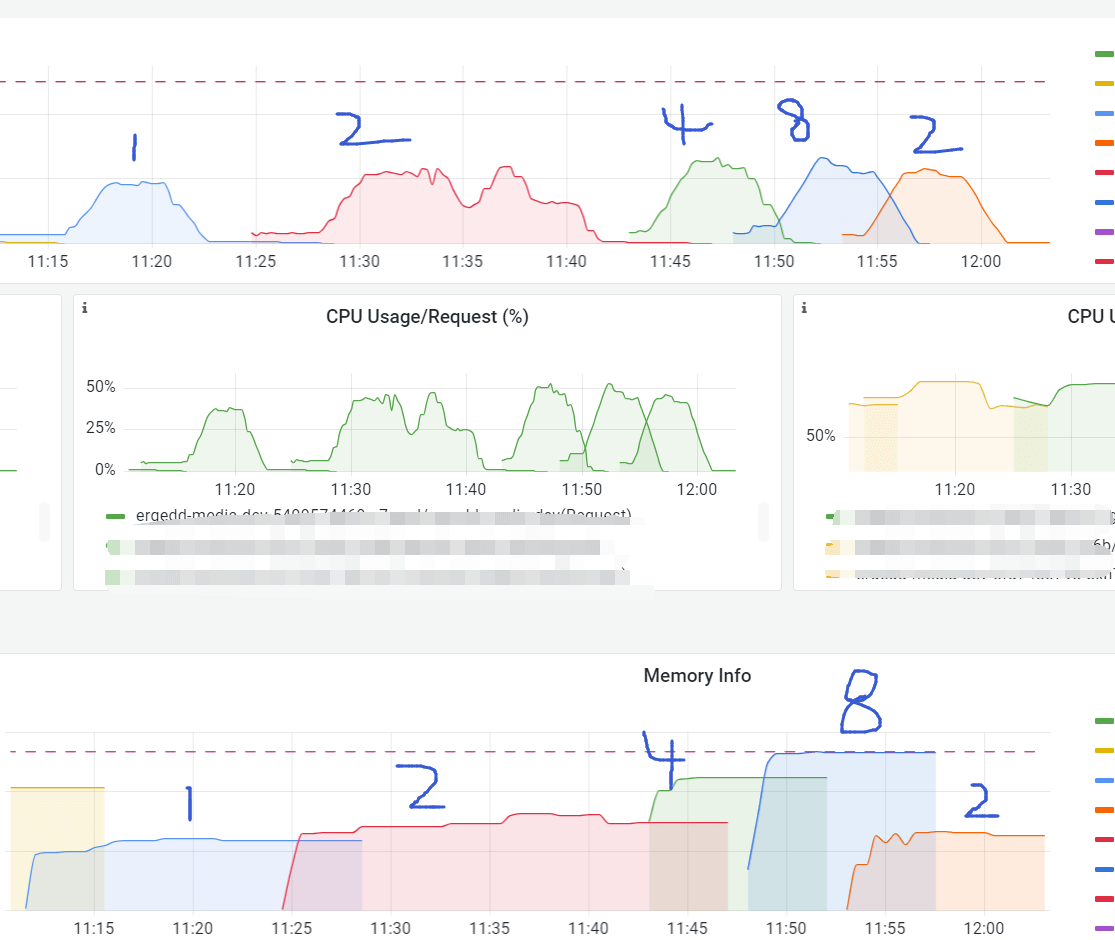
Final configuration: workers=2 with opcache.enable_cli=0 (saves ~60MB RAM per worker).
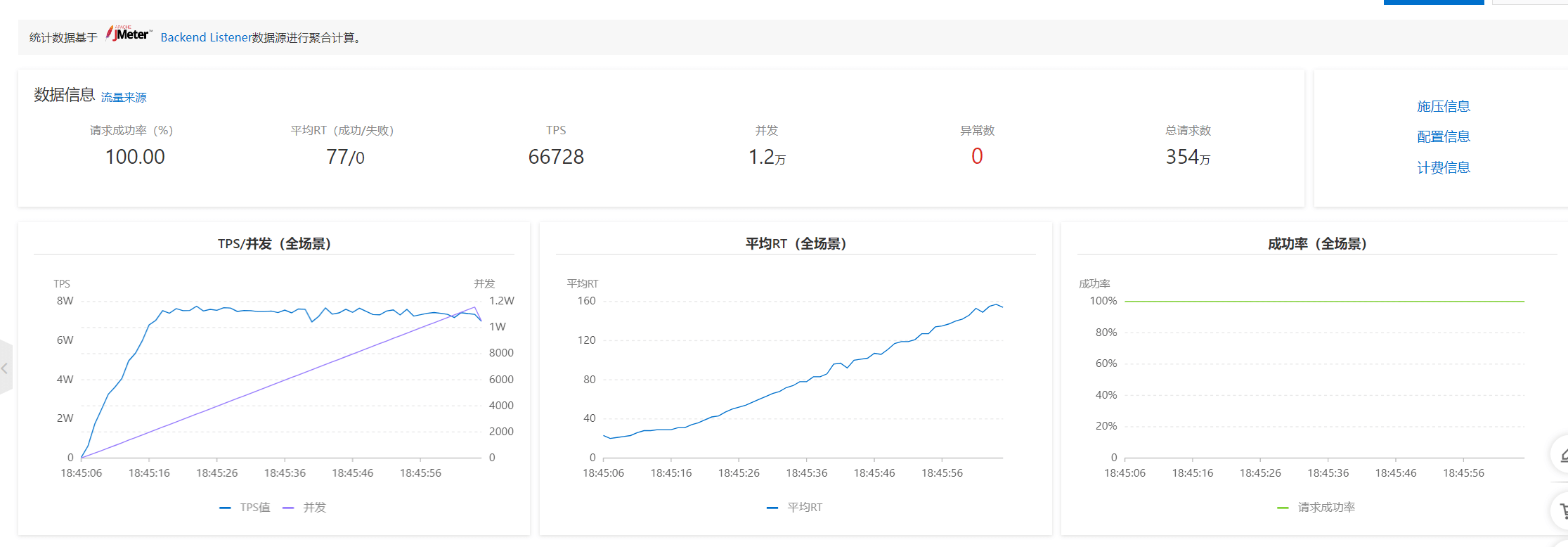
Golang Benchmark
For comparison: Go service (0.5vCPU/128MB * 150 pods) performance:
Notes
Results are reference only. Always conduct your own load testing for production configurations.